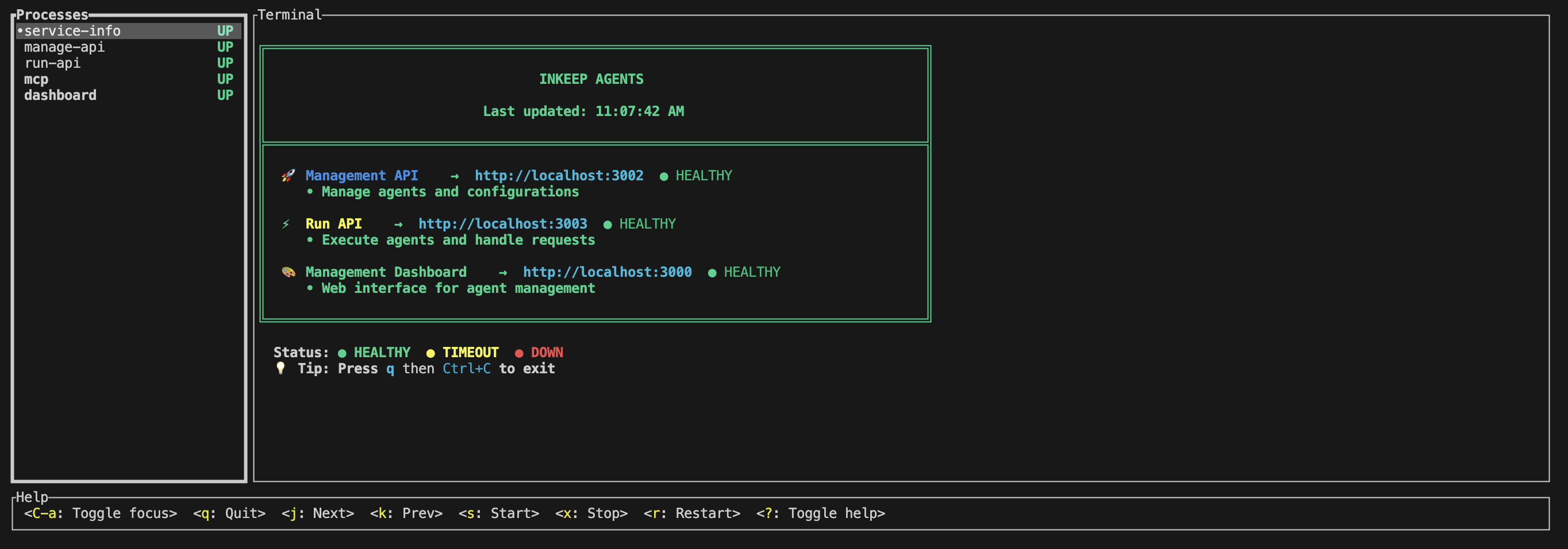
 * The `service-info` tab displays the health of each running service.
* The `manage-api` tab contains logs for all database operations. This is useful primarily for debugging issues with [`inkeep push`](/typescript-sdk/cli-reference#inkeep-push).
* The `run-api` tab contains logs for all agent execution and tool calls. This is useful for debugging issues with your agent's behavior.
* The `mcp` tab contains logs for your [custom MCP servers](/guides/mcp-servers/custom-mcp-servers).
* The `dashboard` tab displays logs for the [Visual Builder](/visual-builder/sub-agents) dashboard.
To terminate the running services, click press `q` or `esc` in the terminal.
## CLI Issues
### Login fails or browser shows "connection refused"
* Verify the dashboard is running (`inkeep dev` or check Docker services)
* Check the manage UI URL in your profile: `inkeep profile current`
* Common cause: profile has a wrong port — re-create with `inkeep profile add`
### "Device code expired" during login
This usually means the manage UI was unreachable when you tried to approve the device code.
* Check: `inkeep profile current` — verify the **Manage UI** URL is correct and accessible in your browser
* For local development, the default manage UI runs on `http://localhost:3000`
### Push fails with authentication errors
* Ensure you've logged in for the active profile: `inkeep login`
* Local profiles with `credential: none` don't require login — the local server accepts unauthenticated requests
* Check which profile is active: `inkeep profile current`
## Authentication Issues (Local Development)
If auto-login isn't working when you open `http://localhost:3000`:
* **You recently logged out**: After clicking "Log out", a `dev-logged-out` cookie prevents auto-login so you can test login flows. To restore auto-login, clear your cookies or restart your browser.
* **`pnpm db:auth:init` not run**: The admin user must exist in the database. Run `pnpm db:auth:init` to create it.
* **API not running**: The auto-login proxy calls `POST /api/auth/dev-session` on the API server. Make sure the API is running on `localhost:3002`.
* **Bypass secret missing from `.env`**: Ensure `INKEEP_AGENTS_MANAGE_API_BYPASS_SECRET` is set in your `.env` file. The proxy uses this to authenticate with the API. Check the server console for `[proxy]` warnings.
* **Credentials missing from `.env`**: Ensure `INKEEP_AGENTS_MANAGE_UI_USERNAME` is set in your `.env` file. The password env var is only used by `pnpm db:auth:init` to create the admin user, not for auto-login.
## Common Configuration Issues
### General Configuration Issues
* **Missing environment variables**: Ensure all required env vars are set
* **Incorrect API endpoints**: Verify you're using the right URLs
* **Network connectivity**: Check firewall and proxy settings
* **Version mismatches**: Ensure all packages are compatible
### MCP Server Connection Issues
* **MCP not able to connect**:
* Check that the MCP server is running and accessible
* **401 Unauthorized errors**:
* Verify that credentials are properly configured and valid
* **Connection timeouts**:
* Ensure network connectivity and firewall settings allow connections
### AI Provider Configuration Problems
* **AI Provider key not defined or invalid**:
* Ensure you have one of these environment variables set: `ANTHROPIC_API_KEY`, `OPENAI_API_KEY`, or `GOOGLE_GENERATIVE_AI_API_KEY`
* Verify the API key is valid and has sufficient credits
* Check that the key hasn't expired or been revoked
* **GPT-5 access issues**:
* Individual users cannot access GPT-5 as it requires organization verification
* Use GPT-4 or other available models instead
* Contact OpenAI support if you need GPT-5 access for your organization
### Credit and Rate Limiting Issues
* **Running out of credits**:
* Monitor your OpenAI usage and billing
* Set up usage alerts to prevent unexpected charges
* **Rate limiting by AI providers**:
* Especially common with high-frequency operations like summarizers
* Monitor your API usage patterns and adjust accordingly
### Context Fetcher Issues
* **Context fetcher timeouts**:
* Check that external services are responding within expected timeframes
## Error Retry Behavior
When calling agents the system automatically retries certain errors using exponential backoff.
The following errors are automatically retried:
| Status Code | Meaning |
| ----------- | -------------------------------- |
| `429` | Too Many Requests (rate limited) |
| `500` | Internal Server Error |
| `502` | Bad Gateway |
| `503` | Service Unavailable |
| `504` | Gateway Timeout |
These transient network issues are also automatically retried:
* Network connectivity failures
* Connection timeouts
* `ECONNRESET` — Connection reset by peer
* `ECONNREFUSED` — Connection refused (network level)
* `ENOTFOUND` — DNS lookup failures
* Fetch/request failures
# Inkeep API (/api-reference)
Explore the Inkeep Agents API endpoints for managing, running, and evaluating agents.
import { source } from '@/lib/source';
* The `service-info` tab displays the health of each running service.
* The `manage-api` tab contains logs for all database operations. This is useful primarily for debugging issues with [`inkeep push`](/typescript-sdk/cli-reference#inkeep-push).
* The `run-api` tab contains logs for all agent execution and tool calls. This is useful for debugging issues with your agent's behavior.
* The `mcp` tab contains logs for your [custom MCP servers](/guides/mcp-servers/custom-mcp-servers).
* The `dashboard` tab displays logs for the [Visual Builder](/visual-builder/sub-agents) dashboard.
To terminate the running services, click press `q` or `esc` in the terminal.
## CLI Issues
### Login fails or browser shows "connection refused"
* Verify the dashboard is running (`inkeep dev` or check Docker services)
* Check the manage UI URL in your profile: `inkeep profile current`
* Common cause: profile has a wrong port — re-create with `inkeep profile add`
### "Device code expired" during login
This usually means the manage UI was unreachable when you tried to approve the device code.
* Check: `inkeep profile current` — verify the **Manage UI** URL is correct and accessible in your browser
* For local development, the default manage UI runs on `http://localhost:3000`
### Push fails with authentication errors
* Ensure you've logged in for the active profile: `inkeep login`
* Local profiles with `credential: none` don't require login — the local server accepts unauthenticated requests
* Check which profile is active: `inkeep profile current`
## Authentication Issues (Local Development)
If auto-login isn't working when you open `http://localhost:3000`:
* **You recently logged out**: After clicking "Log out", a `dev-logged-out` cookie prevents auto-login so you can test login flows. To restore auto-login, clear your cookies or restart your browser.
* **`pnpm db:auth:init` not run**: The admin user must exist in the database. Run `pnpm db:auth:init` to create it.
* **API not running**: The auto-login proxy calls `POST /api/auth/dev-session` on the API server. Make sure the API is running on `localhost:3002`.
* **Bypass secret missing from `.env`**: Ensure `INKEEP_AGENTS_MANAGE_API_BYPASS_SECRET` is set in your `.env` file. The proxy uses this to authenticate with the API. Check the server console for `[proxy]` warnings.
* **Credentials missing from `.env`**: Ensure `INKEEP_AGENTS_MANAGE_UI_USERNAME` is set in your `.env` file. The password env var is only used by `pnpm db:auth:init` to create the admin user, not for auto-login.
## Common Configuration Issues
### General Configuration Issues
* **Missing environment variables**: Ensure all required env vars are set
* **Incorrect API endpoints**: Verify you're using the right URLs
* **Network connectivity**: Check firewall and proxy settings
* **Version mismatches**: Ensure all packages are compatible
### MCP Server Connection Issues
* **MCP not able to connect**:
* Check that the MCP server is running and accessible
* **401 Unauthorized errors**:
* Verify that credentials are properly configured and valid
* **Connection timeouts**:
* Ensure network connectivity and firewall settings allow connections
### AI Provider Configuration Problems
* **AI Provider key not defined or invalid**:
* Ensure you have one of these environment variables set: `ANTHROPIC_API_KEY`, `OPENAI_API_KEY`, or `GOOGLE_GENERATIVE_AI_API_KEY`
* Verify the API key is valid and has sufficient credits
* Check that the key hasn't expired or been revoked
* **GPT-5 access issues**:
* Individual users cannot access GPT-5 as it requires organization verification
* Use GPT-4 or other available models instead
* Contact OpenAI support if you need GPT-5 access for your organization
### Credit and Rate Limiting Issues
* **Running out of credits**:
* Monitor your OpenAI usage and billing
* Set up usage alerts to prevent unexpected charges
* **Rate limiting by AI providers**:
* Especially common with high-frequency operations like summarizers
* Monitor your API usage patterns and adjust accordingly
### Context Fetcher Issues
* **Context fetcher timeouts**:
* Check that external services are responding within expected timeframes
## Error Retry Behavior
When calling agents the system automatically retries certain errors using exponential backoff.
The following errors are automatically retried:
| Status Code | Meaning |
| ----------- | -------------------------------- |
| `429` | Too Many Requests (rate limited) |
| `500` | Internal Server Error |
| `502` | Bad Gateway |
| `503` | Service Unavailable |
| `504` | Gateway Timeout |
These transient network issues are also automatically retried:
* Network connectivity failures
* Connection timeouts
* `ECONNRESET` — Connection reset by peer
* `ECONNREFUSED` — Connection refused (network level)
* `ENOTFOUND` — DNS lookup failures
* Fetch/request failures
# Inkeep API (/api-reference)
Explore the Inkeep Agents API endpoints for managing, running, and evaluating agents.
import { source } from '@/lib/source';
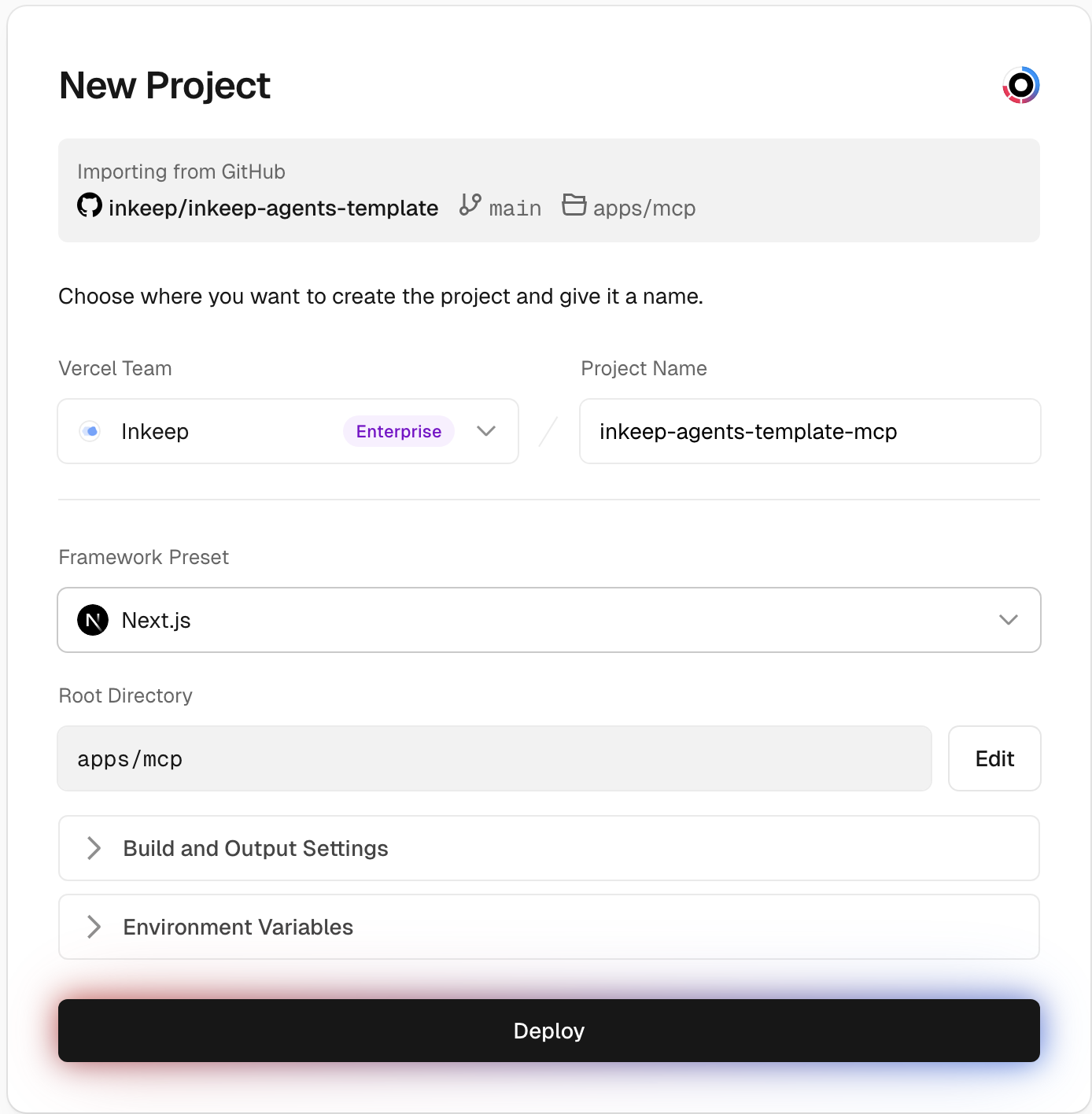
- This occurs when you're not in a Vercel environment or you don't provide a Vercel access token
- Solution: Use a Vercel access token from vercel.com/account/tokens
-
Increase the
timeoutvalue in sandbox configuration -
Consider allocating more
vcpusfor resource-intensive functions - Check Vercel Sandbox limits for your plan
- Ensure dependencies are compatible with Node.js 22
- Check that package versions are specified correctly
- Verify network access to npm registry
-
Reduce
vcpusallocation if functions don't need maximum resources - Optimize function code to execute faster
- Consider caching results when possible
- Use environment variables – Never hardcode credentials
- Start with fewer vCPUs – Scale up only if needed
- Set reasonable timeouts – Prevent runaway executions
- Monitor usage – Track sandbox execution metrics in Vercel dashboard
- Test thoroughly – Verify functions work in sandbox environment before deploying
- Choose the right provider – Use native for VMs/Docker/K8s, Vercel Sandbox for serverless only
For more information on function tools, see:
-
Ensure the workflow file exists at
.github/workflows/deployment-health-check.yml - Verify the workflow is enabled in your repository's Actions settings
- Verify your project is connected to GitHub via Vercel for GitHub
- Ensure the check is selected in Project Settings > Deployment Checks
-
The
/readyendpoint checks database connectivity - Ensure database connection strings are correct in the deployment
- Check database accessibility from the Vercel deployment region
- Increase the cold start wait time if needed
- Use Force Promote from the deployment details page in Vercel

 ### Next steps
* Set up [AI coding for Inkeep](https://docs.inkeep.com/get-started/ai-coding-setup-for-ide) with skills and MCP.
* Learn about [inkeep push / pull](https://docs.inkeep.com/get-started/push-pull) so you can go from `SDK -> Visual Builder` and `Visual Builder -> SDK`.
* Follow our [meeting prep agent tutorial](https://docs.inkeep.com/tutorials/agents/meeting-prep-assistant) to create an agent using the Visual Builder.
* Follow our [fact finder agent tutorial](https://docs.inkeep.com/tutorials/agents/fact-finder) to create an agent using the TypeScript SDK.
# Live Debugger, Traces, and OTEL Telemetry (/get-started/traces)
Set up SigNoz to enable full observability with traces and live debugging capabilities for your agents.
## Overview
The Inkeep Agent Framework provides powerful **traces** and **live debugging** capabilities powered by SigNoz. Setting up SigNoz gives you:
* **Real-time trace visualization** - See exactly how your agents execute step-by-step
* **Live debugging** - Debug agent conversations as they happen
* **Export traces as JSON** - Copy complete traces for offline analysis and debugging
* **Full observability** - Complete OpenTelemetry instrumentation for monitoring
* **Performance insights** - Identify bottlenecks and optimize agent performance
### Next steps
* Set up [AI coding for Inkeep](https://docs.inkeep.com/get-started/ai-coding-setup-for-ide) with skills and MCP.
* Learn about [inkeep push / pull](https://docs.inkeep.com/get-started/push-pull) so you can go from `SDK -> Visual Builder` and `Visual Builder -> SDK`.
* Follow our [meeting prep agent tutorial](https://docs.inkeep.com/tutorials/agents/meeting-prep-assistant) to create an agent using the Visual Builder.
* Follow our [fact finder agent tutorial](https://docs.inkeep.com/tutorials/agents/fact-finder) to create an agent using the TypeScript SDK.
# Live Debugger, Traces, and OTEL Telemetry (/get-started/traces)
Set up SigNoz to enable full observability with traces and live debugging capabilities for your agents.
## Overview
The Inkeep Agent Framework provides powerful **traces** and **live debugging** capabilities powered by SigNoz. Setting up SigNoz gives you:
* **Real-time trace visualization** - See exactly how your agents execute step-by-step
* **Live debugging** - Debug agent conversations as they happen
* **Export traces as JSON** - Copy complete traces for offline analysis and debugging
* **Full observability** - Complete OpenTelemetry instrumentation for monitoring
* **Performance insights** - Identify bottlenecks and optimize agent performance
-
file_name: The name of the file containing the snippet -
pages: The page numbers where the snippet appears (for PDFs and DOCX files) -
content: The actual text content of the snippet
-
file_name: The name of the file containing the snippet -
pages: The page numbers where the snippet appears (for PDFs and DOCX files) -
content: The actual text content of the snippet
`anthropic/claude-opus-4-7`
`anthropic/claude-opus-4-6`
`anthropic/claude-sonnet-4-6`
`anthropic/claude-sonnet-4-5`
`anthropic/claude-haiku-4-5` | `ANTHROPIC_API_KEY` | | **OpenAI** | `openai/gpt-5.5-pro`
`openai/gpt-5.5`
`openai/gpt-5.4-pro`
`openai/gpt-5.4`
`openai/gpt-5.4-mini`
`openai/gpt-5.4-nano`
`openai/gpt-5.2`
`openai/gpt-5.1`
`openai/gpt-4.1`
`openai/gpt-4.1-mini`
`openai/gpt-5`\* | `OPENAI_API_KEY` | | **Azure OpenAI** | `azure/my-gpt4-deployment`
`azure/my-gpt35-deployment` | `AZURE_API_KEY` | | **Google** | `google/gemini-3.1-pro-preview`
`google/gemini-3.5-flash`
`google/gemini-3.1-flash-lite`
`google/gemini-2.5-pro`
`google/gemini-2.5-flash`
`google/gemini-2.5-flash-lite` | `GOOGLE_GENERATIVE_AI_API_KEY` | | **OpenRouter** | `openrouter/anthropic/claude-sonnet-4-0`
`openrouter/meta-llama/llama-3.1-405b` | `OPENROUTER_API_KEY` | | **Gateway** | `gateway/openai/gpt-4.1-mini` | `AI_GATEWAY_API_KEY` | | **NVIDIA NIM** | `nim/nvidia/llama-3.3-nemotron-super-49b-v1.5`
`nim/nvidia/nemotron-4-340b-instruct` | `NIM_API_KEY` | | **Custom OpenAI-compatible** | `custom/my-custom-model`
`custom/llama-3-custom` | `CUSTOM_LLM_API_KEY` | | **Mock** | `mock/default` | None required |
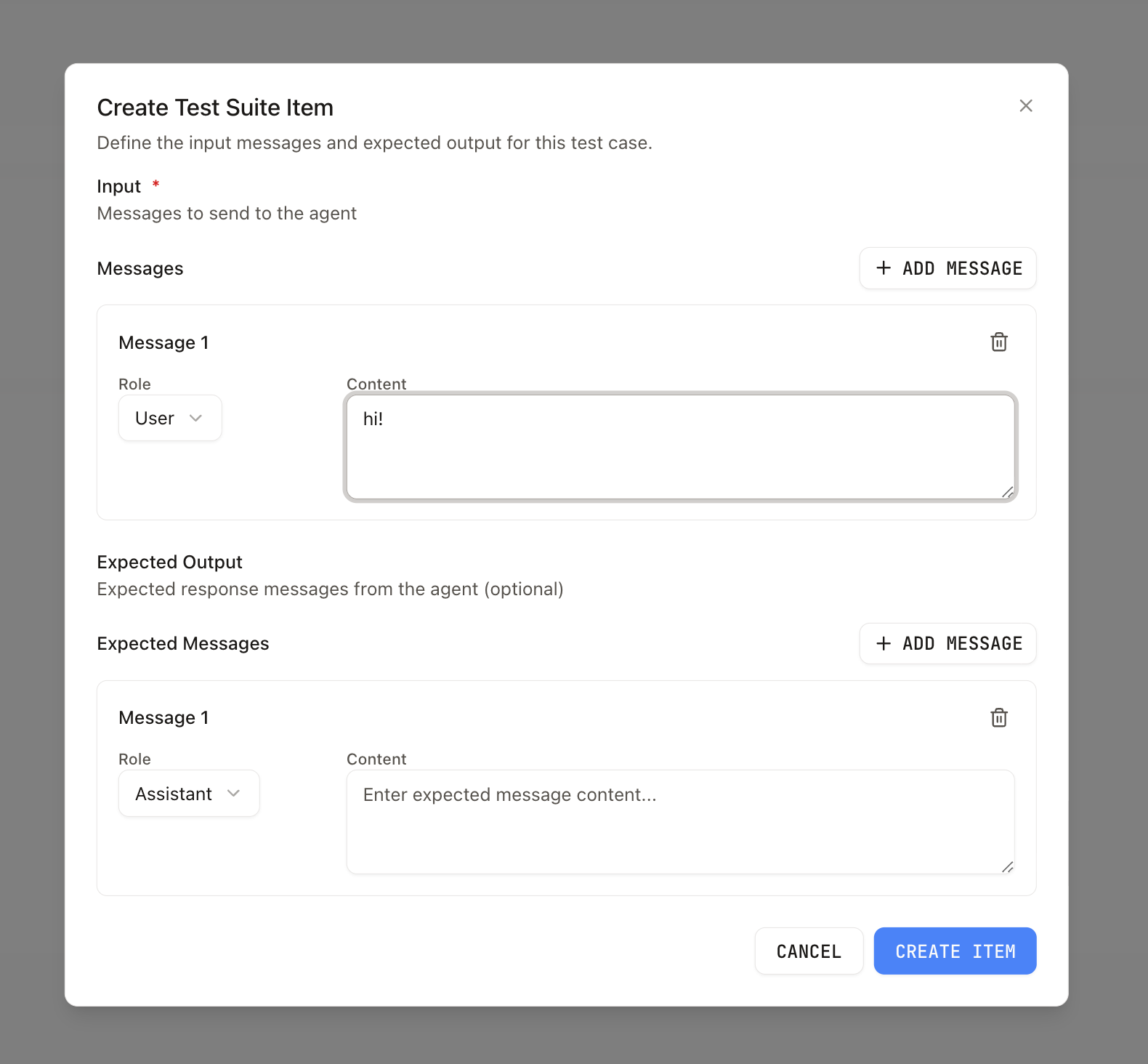 ### Bulk upload from CSV
From the **Items** tab on a test suite, choose **Upload CSV** to create many items at once. The file must be UTF-8 and include a header row.
Recognized headers (case-insensitive):
* **input** (required)
* **expectedOutput** (optional)
Each cell can contain either:
* **Plain text** — a single-turn input becomes `{ messages: [{ role: 'user', content: '
### Bulk upload from CSV
From the **Items** tab on a test suite, choose **Upload CSV** to create many items at once. The file must be UTF-8 and include a header row.
Recognized headers (case-insensitive):
* **input** (required)
* **expectedOutput** (optional)
Each cell can contain either:
* **Plain text** — a single-turn input becomes `{ messages: [{ role: 'user', content: '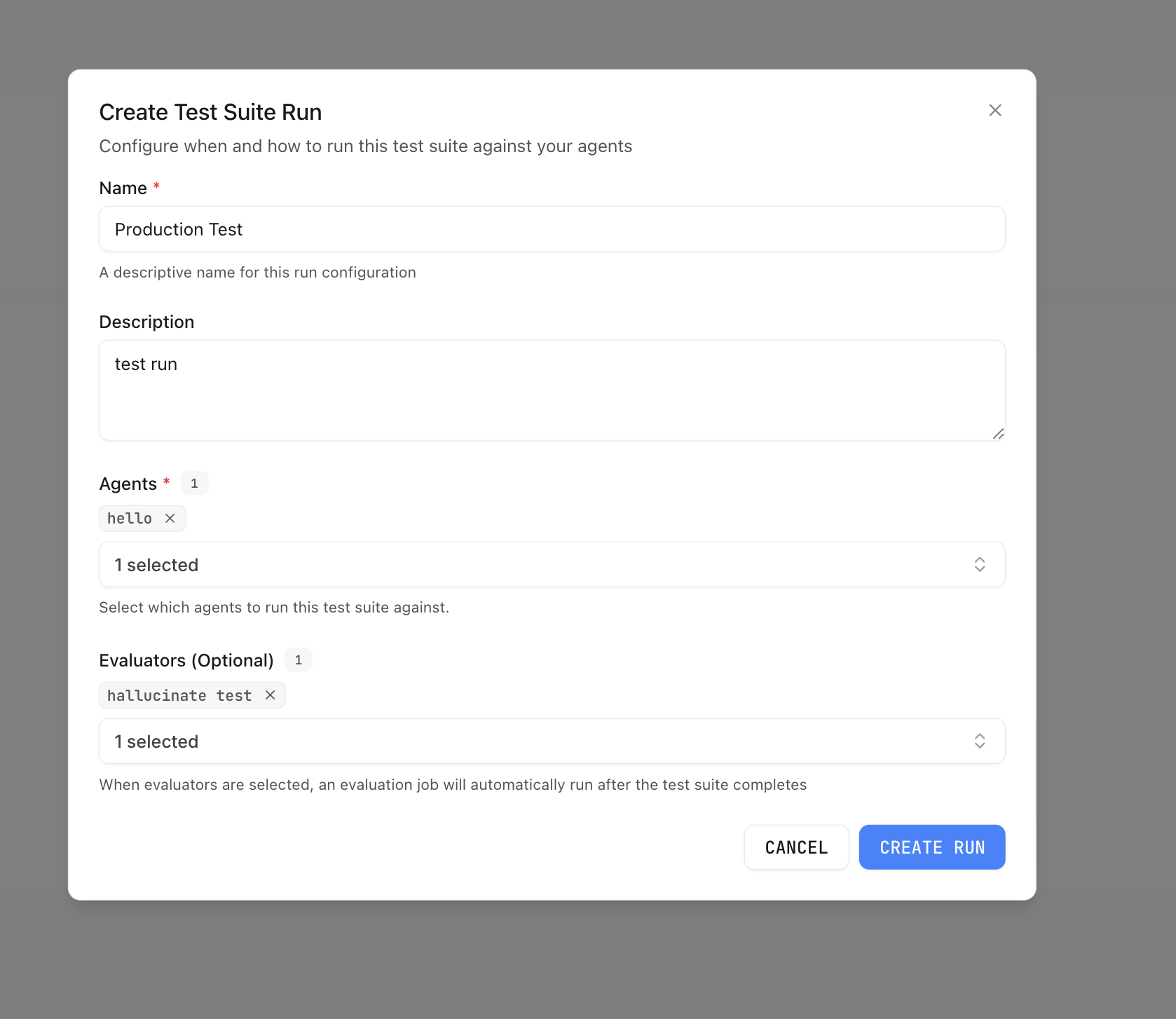 Open a run to see per-item invocations, conversation links, and evaluation output when evaluators are configured.
### Rerun a past run
Each row on the **Runs** tab has a **Rerun** action, and the run detail page exposes a **Rerun** button in the header. Triggering a rerun creates a new row in the runs table using:
* The **current** items in the test suite (any items you've added since the source run are included; deleted items are skipped).
* The **same run configuration** (agents, name) as the source run.
* The **same evaluators** that were attached to the source run, unless you pass overrides.
The rerun endpoint is `POST .../dataset-runs/{runId}/rerun`. The response includes the new `datasetRunId` so you can navigate straight to the in-progress run. Runs that were not created from a run configuration can't be rerun — the button is disabled for those rows.
## Programmatic access
| Surface | Use for |
| ---------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------- |
| [Evaluations API reference](/api-reference/evaluations) | CRUD test suites and items, agent links, run configs, trigger runs (`POST .../dataset-run-configs/{id}/run`), list runs and results |
| [TypeScript SDK: Evaluations](/typescript-sdk/evaluations) | `EvaluationClient` helpers (`listDatasets`, `createDataset`, `createDatasetItem`, `createDatasetItems`, etc.) |
Listing test suites supports an optional `agentId` query parameter on the list endpoint to restrict results to suites linked to that agent.
## Related
* [Evaluations in Visual Builder](/visual-builder/evaluations) — Evaluators, batch evaluations over conversations, and continuous tests
* [Evaluations API reference](/api-reference/evaluations)
* [TypeScript SDK: Evaluations](/typescript-sdk/evaluations)
# Environment Configuration (/community/contributing/environment-configuration)
How to configure the environment variables for the Inkeep Agent Framework
## Overview
The Inkeep Agents framework uses a **centralized environment configuration**. This approach provides a single source of truth for all environment variables across the monorepo, eliminating duplication and simplifying configuration management.
## Configuration Structure
### Single Root Configuration
All packages in the monorepo reference a **single `.env` file** at the repository root. This is different from the typical approach of having separate `.env` files per package.
```
agents-4/
├── .env # Main configuration (gitignored)
├── .env.example # Template with all variables
└── packages/
└── agents-core/
└── src/env.ts # Centralized env loader
```
### Loading Priority
Environment variables are loaded in the following order (highest priority first):
1. **`/package-name/.env`** Package specific configuration
2. **`.env`** - Main configuration file
3. **`~/.inkeep/config`** - User-global settings (shared across all repo copies)
4. **`.env.example`** - Default values
This hierarchy allows for flexible configuration management across different scenarios. If you have .env or .env.local in a package directory, they will override the root .env or .env.local for that package.
## Use Cases
### 1. Basic Local Development
For local development, `pnpm setup-dev` creates your `.env` and initializes databases. You only need to add your AI provider API keys:
```bash
# Run setup (creates .env, starts databases, runs migrations)
pnpm setup-dev
# Add your API keys to .env
vim .env
# Start development
pnpm dev
```
## Troubleshooting
### Auto-login not working
The Manage UI auto-logs you in during local development via a server-side proxy (`proxy.ts`). If you're redirected to the login page instead, your `.env` is likely missing the required variables. Ensure these are set:
```bash
INKEEP_AGENTS_MANAGE_UI_USERNAME=admin@example.com
INKEEP_AGENTS_MANAGE_UI_PASSWORD=
Open a run to see per-item invocations, conversation links, and evaluation output when evaluators are configured.
### Rerun a past run
Each row on the **Runs** tab has a **Rerun** action, and the run detail page exposes a **Rerun** button in the header. Triggering a rerun creates a new row in the runs table using:
* The **current** items in the test suite (any items you've added since the source run are included; deleted items are skipped).
* The **same run configuration** (agents, name) as the source run.
* The **same evaluators** that were attached to the source run, unless you pass overrides.
The rerun endpoint is `POST .../dataset-runs/{runId}/rerun`. The response includes the new `datasetRunId` so you can navigate straight to the in-progress run. Runs that were not created from a run configuration can't be rerun — the button is disabled for those rows.
## Programmatic access
| Surface | Use for |
| ---------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------- |
| [Evaluations API reference](/api-reference/evaluations) | CRUD test suites and items, agent links, run configs, trigger runs (`POST .../dataset-run-configs/{id}/run`), list runs and results |
| [TypeScript SDK: Evaluations](/typescript-sdk/evaluations) | `EvaluationClient` helpers (`listDatasets`, `createDataset`, `createDatasetItem`, `createDatasetItems`, etc.) |
Listing test suites supports an optional `agentId` query parameter on the list endpoint to restrict results to suites linked to that agent.
## Related
* [Evaluations in Visual Builder](/visual-builder/evaluations) — Evaluators, batch evaluations over conversations, and continuous tests
* [Evaluations API reference](/api-reference/evaluations)
* [TypeScript SDK: Evaluations](/typescript-sdk/evaluations)
# Environment Configuration (/community/contributing/environment-configuration)
How to configure the environment variables for the Inkeep Agent Framework
## Overview
The Inkeep Agents framework uses a **centralized environment configuration**. This approach provides a single source of truth for all environment variables across the monorepo, eliminating duplication and simplifying configuration management.
## Configuration Structure
### Single Root Configuration
All packages in the monorepo reference a **single `.env` file** at the repository root. This is different from the typical approach of having separate `.env` files per package.
```
agents-4/
├── .env # Main configuration (gitignored)
├── .env.example # Template with all variables
└── packages/
└── agents-core/
└── src/env.ts # Centralized env loader
```
### Loading Priority
Environment variables are loaded in the following order (highest priority first):
1. **`/package-name/.env`** Package specific configuration
2. **`.env`** - Main configuration file
3. **`~/.inkeep/config`** - User-global settings (shared across all repo copies)
4. **`.env.example`** - Default values
This hierarchy allows for flexible configuration management across different scenarios. If you have .env or .env.local in a package directory, they will override the root .env or .env.local for that package.
## Use Cases
### 1. Basic Local Development
For local development, `pnpm setup-dev` creates your `.env` and initializes databases. You only need to add your AI provider API keys:
```bash
# Run setup (creates .env, starts databases, runs migrations)
pnpm setup-dev
# Add your API keys to .env
vim .env
# Start development
pnpm dev
```
## Troubleshooting
### Auto-login not working
The Manage UI auto-logs you in during local development via a server-side proxy (`proxy.ts`). If you're redirected to the login page instead, your `.env` is likely missing the required variables. Ensure these are set:
```bash
INKEEP_AGENTS_MANAGE_UI_USERNAME=admin@example.com
INKEEP_AGENTS_MANAGE_UI_PASSWORD= ### Step 2: Enter a project
Once you're logged in, you'll be redirected to the Inkeep Enterprise project overview page. If you are part of a team, you might see a list of existing projects like this:
### Step 2: Enter a project
Once you're logged in, you'll be redirected to the Inkeep Enterprise project overview page. If you are part of a team, you might see a list of existing projects like this:
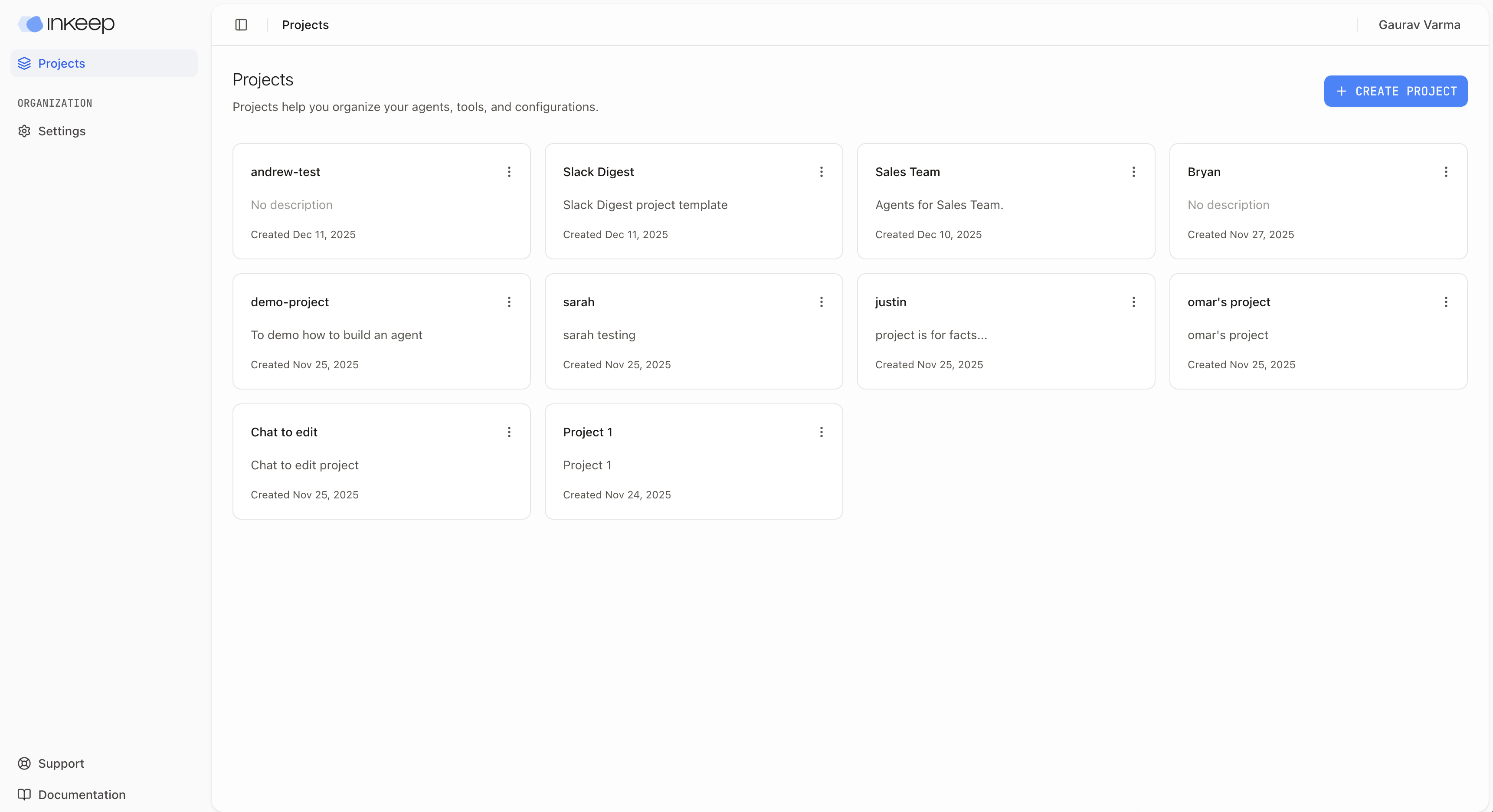 If you are part of a team, click into the project your team has created. If you are not part of a team, you can create a new project by clicking the "Create Project" button.
### Step 3: Inspect the project
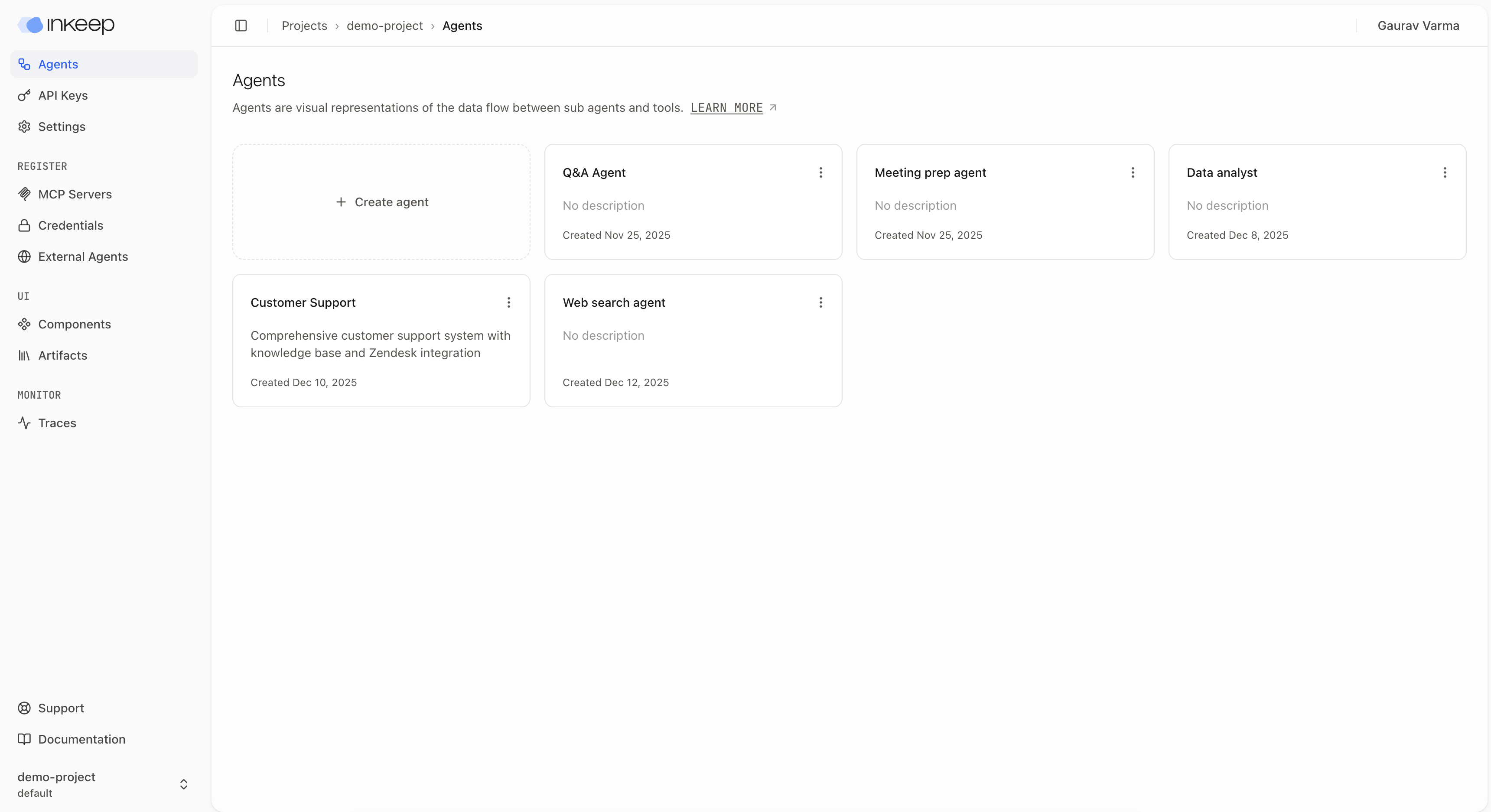
Once you're in the project, you'll see the project overview page. You can see the list of agents that are part of the project.
If you are part of a team, click into the project your team has created. If you are not part of a team, you can create a new project by clicking the "Create Project" button.
### Step 3: Inspect the project
Once you're in the project, you'll see the project overview page. You can see the list of agents that are part of the project.
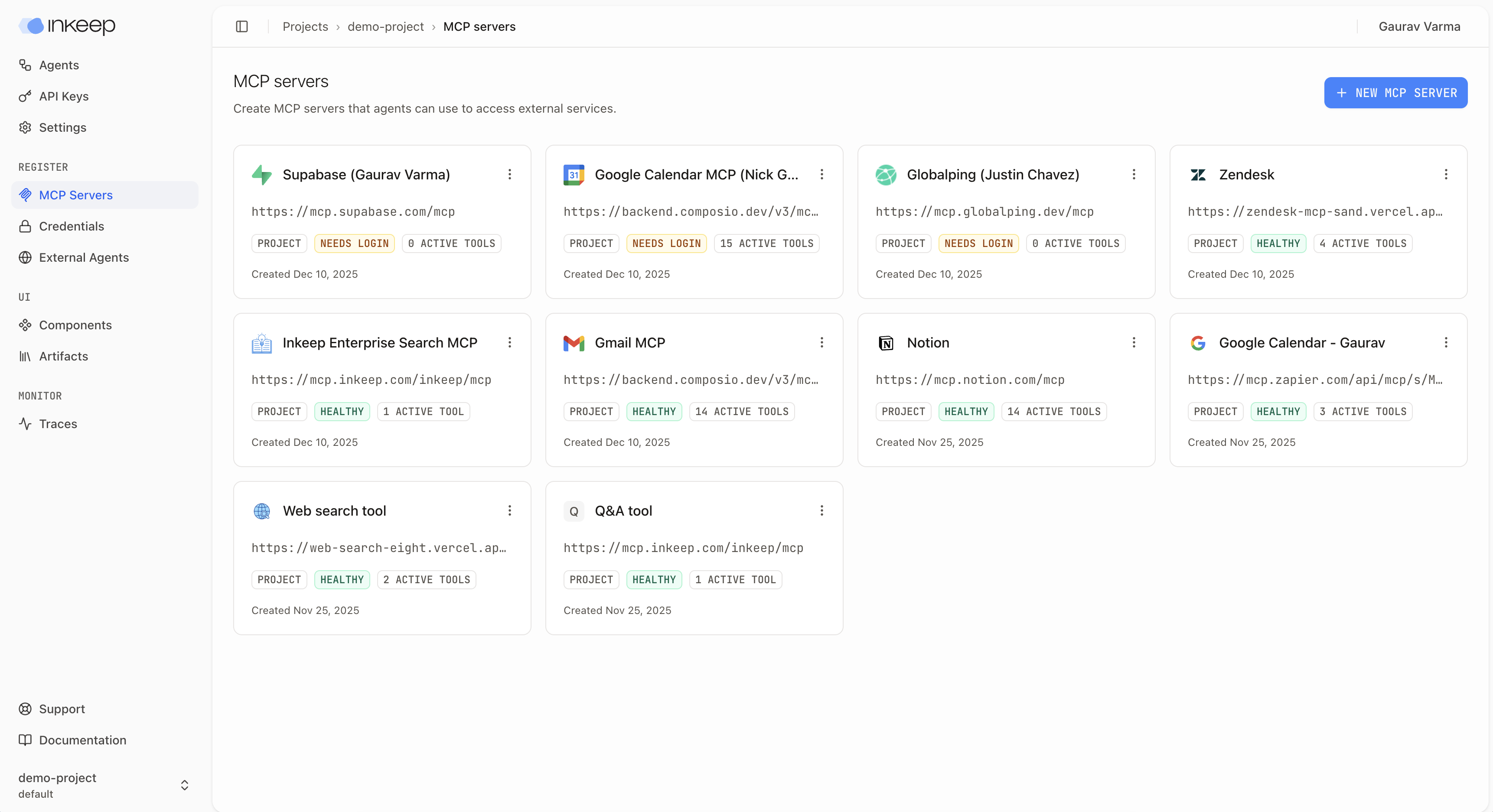
 In the MCP Servers section, you can see the list of MCP servers that are part of the project:
In the MCP Servers section, you can see the list of MCP servers that are part of the project:
 ### Step 5: Try the agent
Once Inkeep has built your agent, try it out by clicking the "Try it" button.
### Step 6: Edit the agent
You can edit your agent by dragging and dropping new sub agents and tools onto the canvas. Here, we'll extend our knowledge agent to use a web search agent if it needs to find more information.
### Next Steps
### Step 5: Try the agent
Once Inkeep has built your agent, try it out by clicking the "Try it" button.
### Step 6: Edit the agent
You can edit your agent by dragging and dropping new sub agents and tools onto the canvas. Here, we'll extend our knowledge agent to use a web search agent if it needs to find more information.
### Next Steps
{title || 'Schedule a meeting'}
Pick a time that works — calendar invite sent automatically
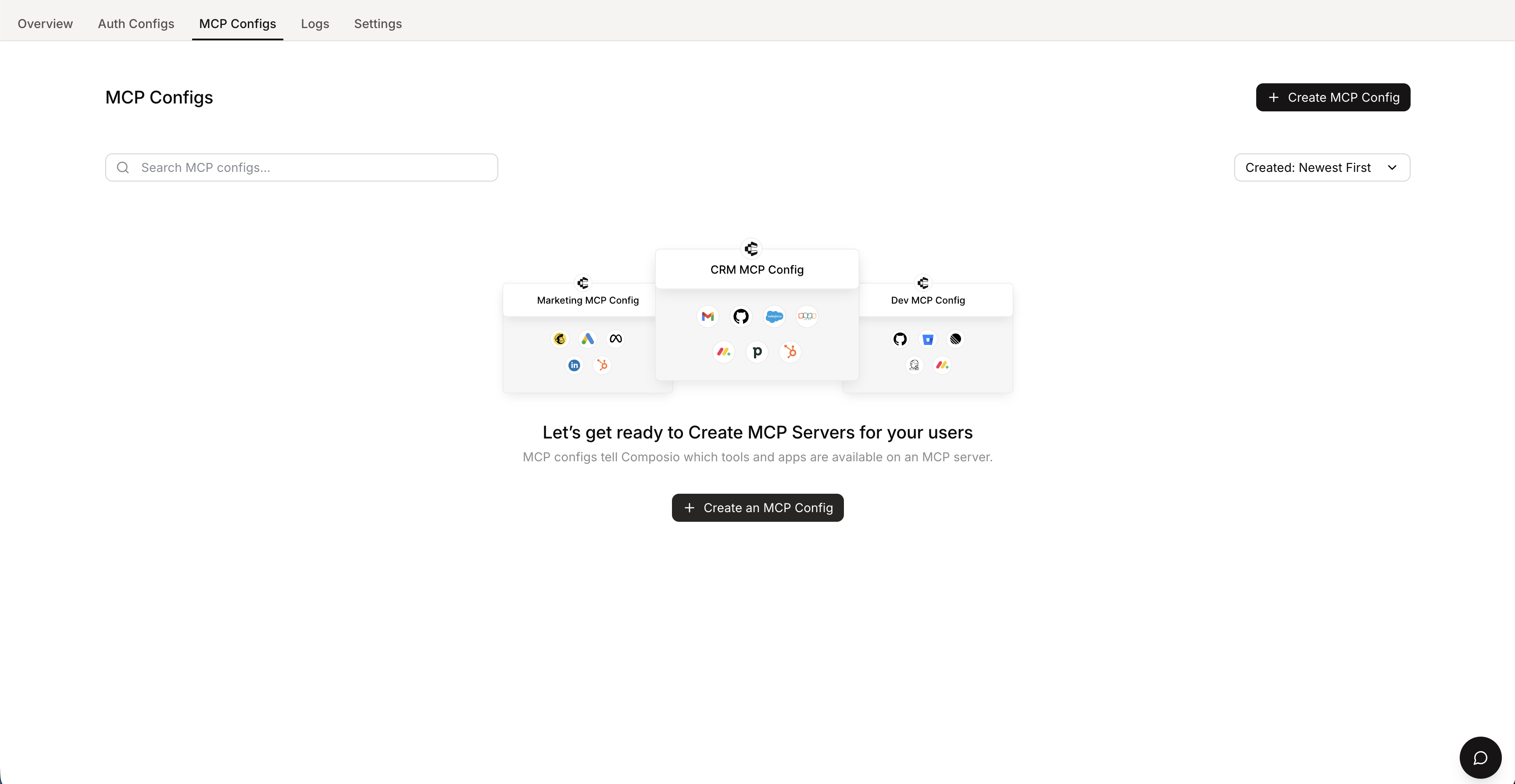 ### Step 3: Retrieve Your API Key
Copy your Composio API key from the Settings tab.
### Step 3: Retrieve Your API Key
Copy your Composio API key from the Settings tab.
 ### Step 4: Add API Key to Environment
Add your Composio API key to your root `.env` file:
```
COMPOSIO_API_KEY=your-composio-api-key
```
### Step 5: Restart and Verify
Restart your development servers by pressing Control + C and running `pnpm dev` again (pressing `r` will not work).
Open the Visual Builder and navigate to the MCP Servers tab. Click **+New MCP Server**, then select the **Popular MCP Servers** tab and search for "composio" to see your configured Composio MCP servers.
# Build Custom MCP Servers (/guides/mcp-servers/custom-mcp-servers)
Build your own custom MCP servers
## When to Build Custom MCP Servers
Build custom MCP servers when:
* Native servers don't exist for your specific APIs
* You need custom business logic beyond what existing servers provide
* You have proprietary systems that require custom integration
If pre-built servers meet your needs, consider [Native MCP servers](/guides/mcp-servers/native-mcp-servers), [Composio's platform](/guides/mcp-servers/composio-mcp-servers), or [Gram](/guides/mcp-servers/gram) instead.
## Getting Started
The Quick Start workspace includes a Next.js app in the `apps/mcp/app/` directory that you can use to expose your MCP servers.
Each MCP server you create will be exposed on a separate route on this app.
#### Creating from a template
You can add a custom MCP server template from our [template library](https://github.com/inkeep/agents/tree/main/agents-cookbook/template-mcps) for common use cases using the [CLI](/typescript-sdk/cli-reference#inkeep-add).
```bash
inkeep add --mcp [server-name]
```
This will automatically add a custom MCP server template to your Quick Start workspace. After customizing and deploying it, you can register it.
#### Using Vercel's Template
If you want to create a custom MCP server, you can use Vercel's [Next.js MCP template](https://vercel.com/templates/next.js/model-context-protocol-mcp-with-next-js) as a starting point:
### Step 4: Add API Key to Environment
Add your Composio API key to your root `.env` file:
```
COMPOSIO_API_KEY=your-composio-api-key
```
### Step 5: Restart and Verify
Restart your development servers by pressing Control + C and running `pnpm dev` again (pressing `r` will not work).
Open the Visual Builder and navigate to the MCP Servers tab. Click **+New MCP Server**, then select the **Popular MCP Servers** tab and search for "composio" to see your configured Composio MCP servers.
# Build Custom MCP Servers (/guides/mcp-servers/custom-mcp-servers)
Build your own custom MCP servers
## When to Build Custom MCP Servers
Build custom MCP servers when:
* Native servers don't exist for your specific APIs
* You need custom business logic beyond what existing servers provide
* You have proprietary systems that require custom integration
If pre-built servers meet your needs, consider [Native MCP servers](/guides/mcp-servers/native-mcp-servers), [Composio's platform](/guides/mcp-servers/composio-mcp-servers), or [Gram](/guides/mcp-servers/gram) instead.
## Getting Started
The Quick Start workspace includes a Next.js app in the `apps/mcp/app/` directory that you can use to expose your MCP servers.
Each MCP server you create will be exposed on a separate route on this app.
#### Creating from a template
You can add a custom MCP server template from our [template library](https://github.com/inkeep/agents/tree/main/agents-cookbook/template-mcps) for common use cases using the [CLI](/typescript-sdk/cli-reference#inkeep-add).
```bash
inkeep add --mcp [server-name]
```
This will automatically add a custom MCP server template to your Quick Start workspace. After customizing and deploying it, you can register it.
#### Using Vercel's Template
If you want to create a custom MCP server, you can use Vercel's [Next.js MCP template](https://vercel.com/templates/next.js/model-context-protocol-mcp-with-next-js) as a starting point:
{props.actions.map((action) => (
))}
),
}
const aiChatSettings: InkeepAIChatSettings = {
appId: process.env.REACT_APP_INKEEP_APP_ID,
chatFunctionsRef,
components,
}
return
chatFunctionsRef.current?.submitMessage(
'Tell me more about the ' + props.name + ' plan. What is included and are there any limits?'
)
}
>
),
}
const aiChatSettings: InkeepAIChatSettings = {
appId: process.env.REACT_APP_INKEEP_APP_ID,
chatFunctionsRef,
components,
}
return {props.name}
{props.price}
-
{props.features.map((f) => (
- {f} ))}
{
chatFunctionsRef.current?.updateInputMessage(
'I would like to learn more about ' + props.name
)
chatFunctionsRef.current?.focusInput()
}}
>
),
```
```js title="JavaScript"
PlanCard: (props, target) => {
const card = document.createElement("div");
card.className =
"border border-gray-200 rounded-xl p-4 cursor-pointer hover:border-indigo-500 transition-colors";
const title = document.createElement("div");
title.textContent = props.name;
title.className = "font-semibold";
const price = document.createElement("div");
price.textContent = props.price;
price.className = "text-xl font-bold my-2";
card.append(title, price);
card.addEventListener("click", () => {
widget.updateInputMessage("I would like to learn more about " + props.name);
widget.focusInput();
});
target.appendChild(card);
},
```
{props.name}
{props.price}
{toolName}
{tool.state}
{tool.input != null && (
{JSON.stringify(tool.input, null, 2)}
)}
{awaitingApproval && (
{renderMarkdown(String(tool.output))}
)}
{tool.state === 'output-denied' && (
Tool call denied
)}
{tool.state === 'output-error' && (
{tool.errorText}
)}
{messages.map((message) => (
))}
{message.role === "user" ? "👤 User" : "🤖 Assistant"}
{message.parts.map((part, partIndex) => {
const partKey = `${message.id}-${part.type}-${partIndex}`;
if (part.type === "text") {
return (
{part.text}
);
}
return null;
})}
Try asking:
- "What's the weather in New York?"
- "Can you get my location?"
- "Ask me to confirm something"
{messages.map((message) => (
))}
{message.role === "user" ? "👤 User" : "🤖 Assistant"}
{message.parts.map((part, partIndex) => {
const partKey = `${message.id}-${part.type}-${partIndex}`;
if (part.type === "text") {
return (
);
}
return null;
})}
{part.text}
);
}
if (part.type?.startsWith("data-")) {
return (
Data: {JSON.stringify(part, null, 2)}
Try asking:
- "What's the weather in New York?"
- "Can you get my location?"
- "Ask me to confirm something"
Your Tasks ({completedCount}/{totalCount} completed)
{tasks.map((task) => (
{task.title}
))}
{message.parts.map((part) => {
if (part.type === "tool-getWeather") {
switch (part.state) {
case "approval-requested":
return (
);
case "output-available":
return (
))}
);
}
```
Get weather for {part.input.city}?
Weather in {part.input.city}: {String(part.output)}
);
}
}
return null;
})}
Your Tasks ({totalCount} total)
{tasks.map((task) => (
{task.title}
))}
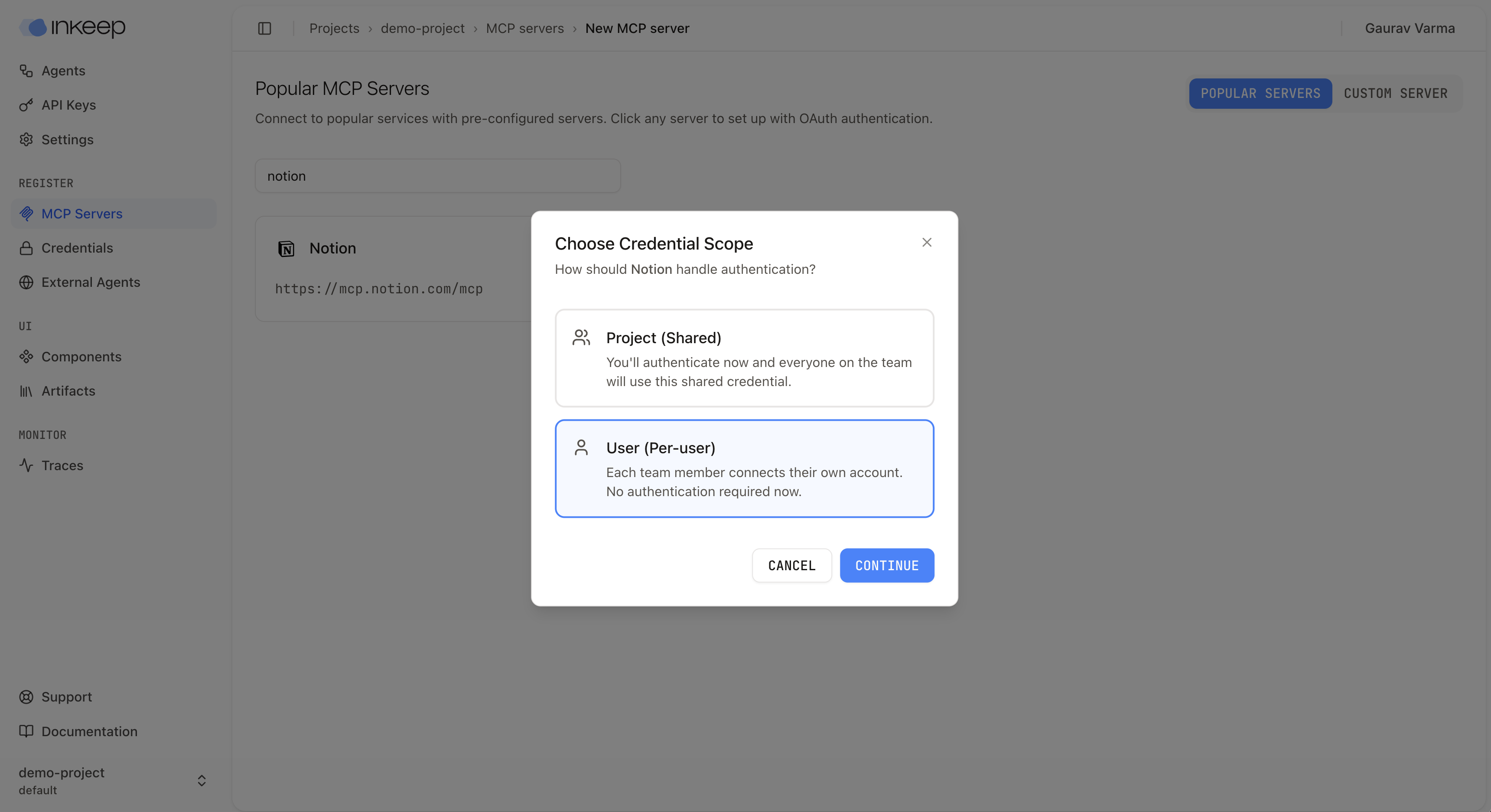 ### Benefits
* **Personal accounts**: Team members can use their own accounts (e.g., their personal Notion workspace, Google Drive, etc.)
* **Better security**: Credentials are not shared across the team
* **Flexible access**: Each team member can connect to different resources based on their own permissions
### Considerations
* **Individual authentication required**: Each team member must authenticate their own credentials before using an agent that relies on user-level MCPs
* **Setup overhead**: New team members need to complete authentication before they can use shared agents
* **Not compatible with triggers**: User-level MCPs cannot be used with [webhook triggers](/visual-builder/triggers/webhooks) or scheduled jobs because these invocation methods don't have user context
## Project-Level MCP Servers
Project-level MCP servers use shared credentials that are configured at the project level. All team members in the project can use these servers without individual authentication.
### Benefits
* **Personal accounts**: Team members can use their own accounts (e.g., their personal Notion workspace, Google Drive, etc.)
* **Better security**: Credentials are not shared across the team
* **Flexible access**: Each team member can connect to different resources based on their own permissions
### Considerations
* **Individual authentication required**: Each team member must authenticate their own credentials before using an agent that relies on user-level MCPs
* **Setup overhead**: New team members need to complete authentication before they can use shared agents
* **Not compatible with triggers**: User-level MCPs cannot be used with [webhook triggers](/visual-builder/triggers/webhooks) or scheduled jobs because these invocation methods don't have user context
## Project-Level MCP Servers
Project-level MCP servers use shared credentials that are configured at the project level. All team members in the project can use these servers without individual authentication.
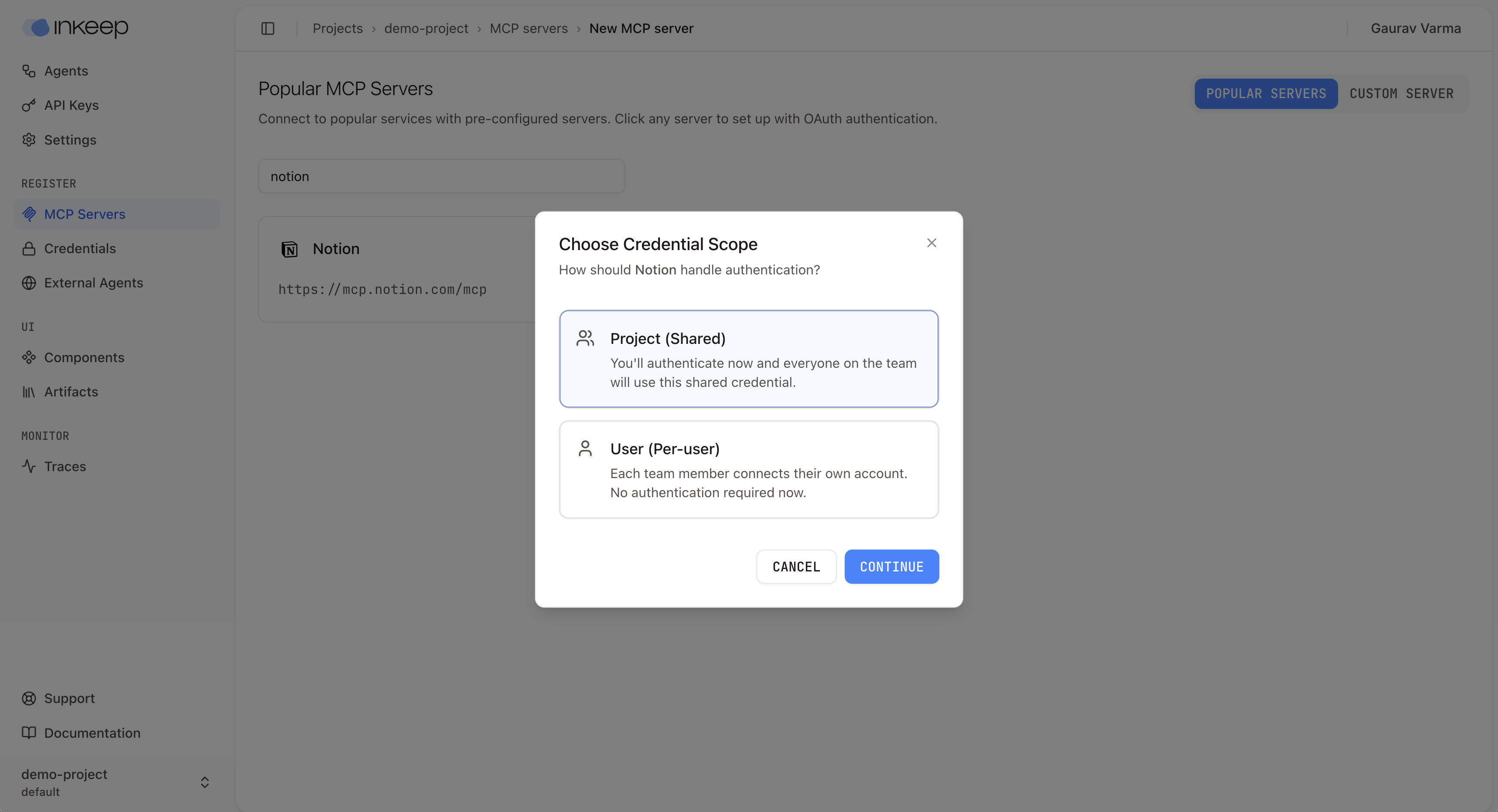 ### Benefits
* **Shared access**: All team members can immediately use agents without additional setup
* **Simplified onboarding**: New team members can start using agents right away
* **Centralized management**: Credentials are managed in one place
### Considerations
* **Shared credentials**: All team members use the same account, which may have security implications
* **Limited flexibility**: Team members cannot use their own accounts or personal resources
### When Sharing an Agent
When sharing an agent with your team, they'll need to authenticate their own credentials for any user-level MCPs before being able to use the agent. Make sure to communicate this requirement to your team members.
# Scheduled Triggers (/visual-builder/triggers/scheduled)
Run your Agents automatically on a recurring schedule or at a specific future time
Scheduled triggers run agents automatically on a recurring schedule (cron) or at a specific future time (one-time). Use them for daily reports, hourly health checks, periodic data syncs, or deferred tasks.
### Benefits
* **Shared access**: All team members can immediately use agents without additional setup
* **Simplified onboarding**: New team members can start using agents right away
* **Centralized management**: Credentials are managed in one place
### Considerations
* **Shared credentials**: All team members use the same account, which may have security implications
* **Limited flexibility**: Team members cannot use their own accounts or personal resources
### When Sharing an Agent
When sharing an agent with your team, they'll need to authenticate their own credentials for any user-level MCPs before being able to use the agent. Make sure to communicate this requirement to your team members.
# Scheduled Triggers (/visual-builder/triggers/scheduled)
Run your Agents automatically on a recurring schedule or at a specific future time
Scheduled triggers run agents automatically on a recurring schedule (cron) or at a specific future time (one-time). Use them for daily reports, hourly health checks, periodic data syncs, or deferred tasks.
 ## Overview
In this guide, you'll add citations to the customer assistant you built in [Setup](/guides/agents/customer-assistant/setup). Once wired up, every fact the assistant references gets saved as a structured **citation artifact** that the Inkeep widget auto-renders as inline source pills and a Sources list below the answer.
## Prerequisites
* You completed the [Customer Assistant setup](/guides/agents/customer-assistant/setup) tutorial — a working sub agent connected to Inkeep Unified Search.
## Why citations are wired this way
### Why an artifact, not a URL in the text
The easy thing for an AI to do is paste `[Title](URL)` into its response. That breaks down fast:
* The agent can hallucinate URLs that look right but don't exist.
* The widget has no structured handle to render rich source cards from — it would just be a link.
* Other sub agents in your project can't reason about "what sources did the previous agent use" because that information is buried in prose.
An **artifact** is a structured record the agent saves. It has a fixed schema (`title`, `url`, `content`, etc.), gets persisted in storage, and can be referenced by ID across the conversation. The widget knows how to find these and render them.
### Why the artifact must be named `citation`
The Inkeep widget has a built-in contract: any artifact named exactly `citation` with `url` as a preview field gets **auto-rendered** — no frontend code required. The widget produces inline source pills with the response text and a Sources list beneath the answer.
If you name it something else (`source`, `reference`, `link`), the artifact still saves correctly, but the widget won't auto-render it. You'd need to write a custom React component to display it. For a customer assistant, you want the auto-render — name it `citation`.
## Create the citation artifact
## Overview
In this guide, you'll add citations to the customer assistant you built in [Setup](/guides/agents/customer-assistant/setup). Once wired up, every fact the assistant references gets saved as a structured **citation artifact** that the Inkeep widget auto-renders as inline source pills and a Sources list below the answer.
## Prerequisites
* You completed the [Customer Assistant setup](/guides/agents/customer-assistant/setup) tutorial — a working sub agent connected to Inkeep Unified Search.
## Why citations are wired this way
### Why an artifact, not a URL in the text
The easy thing for an AI to do is paste `[Title](URL)` into its response. That breaks down fast:
* The agent can hallucinate URLs that look right but don't exist.
* The widget has no structured handle to render rich source cards from — it would just be a link.
* Other sub agents in your project can't reason about "what sources did the previous agent use" because that information is buried in prose.
An **artifact** is a structured record the agent saves. It has a fixed schema (`title`, `url`, `content`, etc.), gets persisted in storage, and can be referenced by ID across the conversation. The widget knows how to find these and render them.
### Why the artifact must be named `citation`
The Inkeep widget has a built-in contract: any artifact named exactly `citation` with `url` as a preview field gets **auto-rendered** — no frontend code required. The widget produces inline source pills with the response text and a Sources list beneath the answer.
If you name it something else (`source`, `reference`, `link`), the artifact still saves correctly, but the widget won't auto-render it. You'd need to write a custom React component to display it. For a customer assistant, you want the auto-render — name it `citation`.
## Create the citation artifact
 ## Overview
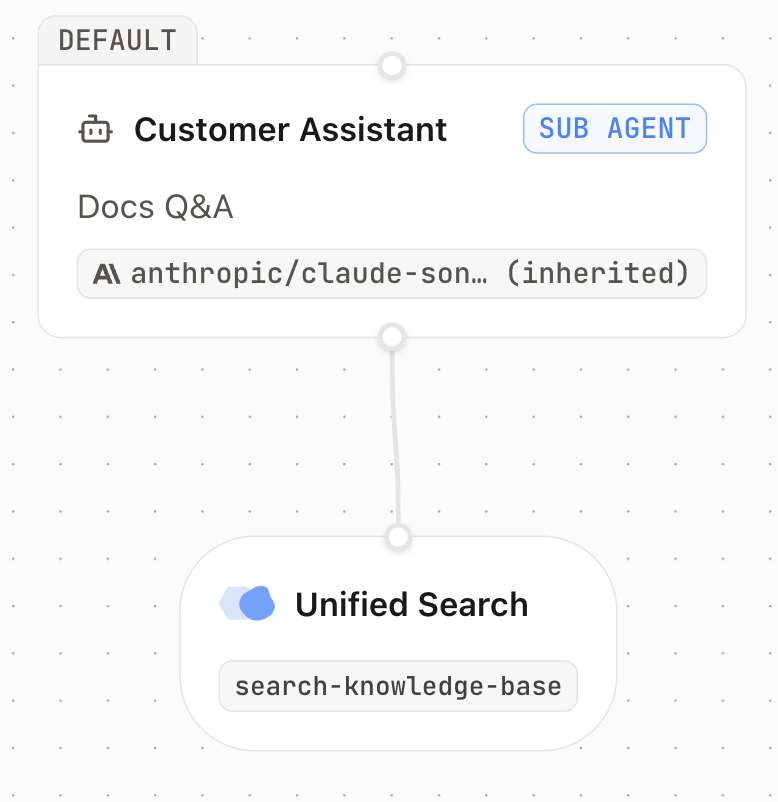
In this tutorial, you'll build a customer-facing AI assistant in the Inkeep Visual Builder. When a customer asks a question about your product, the agent will:
1. Search your knowledge base via Inkeep Unified Search
2. Answer in plain language, grounded in what your docs actually say
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* An Inkeep account with [Inkeep Unified Search](/connect-your-data/inkeep) configured for your product (knowledge base, docs, sources connected)
## Create the agent
## Overview
In this tutorial, you'll build a customer-facing AI assistant in the Inkeep Visual Builder. When a customer asks a question about your product, the agent will:
1. Search your knowledge base via Inkeep Unified Search
2. Answer in plain language, grounded in what your docs actually say
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* An Inkeep account with [Inkeep Unified Search](/connect-your-data/inkeep) configured for your product (knowledge base, docs, sources connected)
## Create the agent
 ## Overview
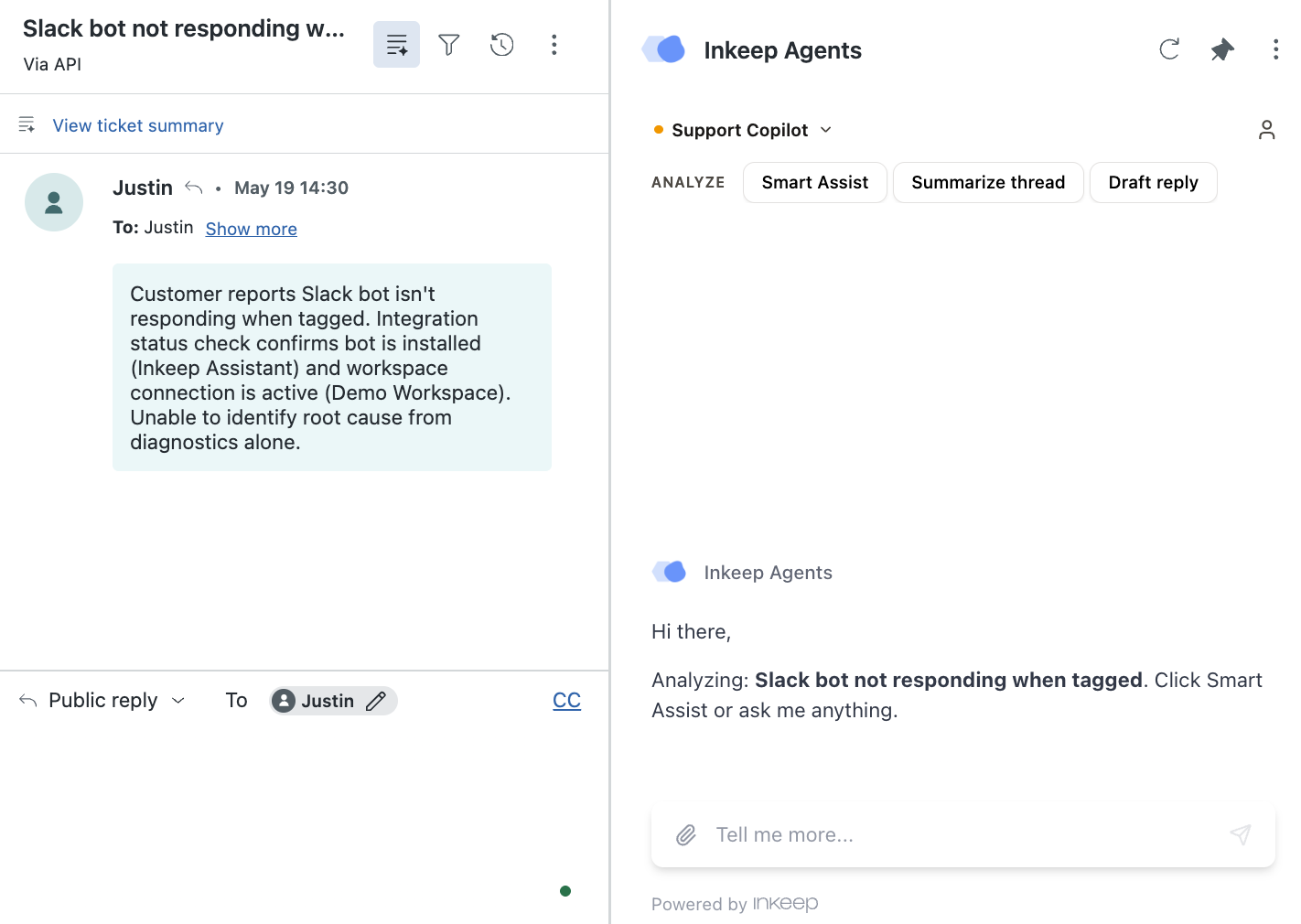
> **Who this is for:** support teams giving their **agents** a copilot inside the **Zendesk ticket sidebar**. (For a copilot embedded in your own product for **logged-in end users**, see [In-Product Copilot](/guides/agents/in-product-copilot).)
Support Copilot puts an Inkeep agent right inside the Zendesk ticket sidebar, working alongside your support team. Its edge is the context it can reach that your customer-facing bot never could: your team's **internal** knowledge — prior resolved threads, internal Slack discussions, and the diagnostics behind past fixes.
When an agent opens a ticket and runs Smart Assist, the copilot will:
1. Read the ticket — the conversation, metadata, and customer details — automatically
2. Search your internal threads for the times your team already solved this exact issue
3. Return structured assistance: a **Draft Answer** the agent can send, the **Relevant Sources** behind it (the internal thread *and* the public article that backed the fix), plus quick replies, clarifying questions, a thread summary, or follow-up tasks as the ticket needs
Everything happens inside the ticket the agent is already working in. No tab-switching, no copy-paste.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* An internal knowledge source exposed as an MCP server — e.g. your internal Slack support channels or a store of past resolved tickets — that returns prior threads and the public source behind each fix. See [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) if you need to create one.
* A Zendesk account, with a Zendesk admin available to approve the app install
## Overview
> **Who this is for:** support teams giving their **agents** a copilot inside the **Zendesk ticket sidebar**. (For a copilot embedded in your own product for **logged-in end users**, see [In-Product Copilot](/guides/agents/in-product-copilot).)
Support Copilot puts an Inkeep agent right inside the Zendesk ticket sidebar, working alongside your support team. Its edge is the context it can reach that your customer-facing bot never could: your team's **internal** knowledge — prior resolved threads, internal Slack discussions, and the diagnostics behind past fixes.
When an agent opens a ticket and runs Smart Assist, the copilot will:
1. Read the ticket — the conversation, metadata, and customer details — automatically
2. Search your internal threads for the times your team already solved this exact issue
3. Return structured assistance: a **Draft Answer** the agent can send, the **Relevant Sources** behind it (the internal thread *and* the public article that backed the fix), plus quick replies, clarifying questions, a thread summary, or follow-up tasks as the ticket needs
Everything happens inside the ticket the agent is already working in. No tab-switching, no copy-paste.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* An internal knowledge source exposed as an MCP server — e.g. your internal Slack support channels or a store of past resolved tickets — that returns prior threads and the public source behind each fix. See [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) if you need to create one.
* A Zendesk account, with a Zendesk admin available to approve the app install
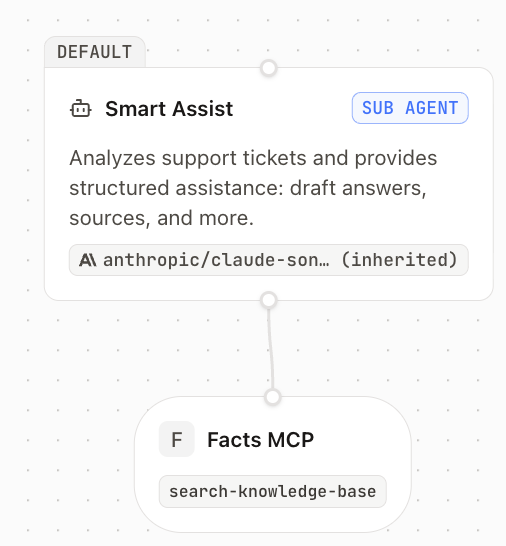
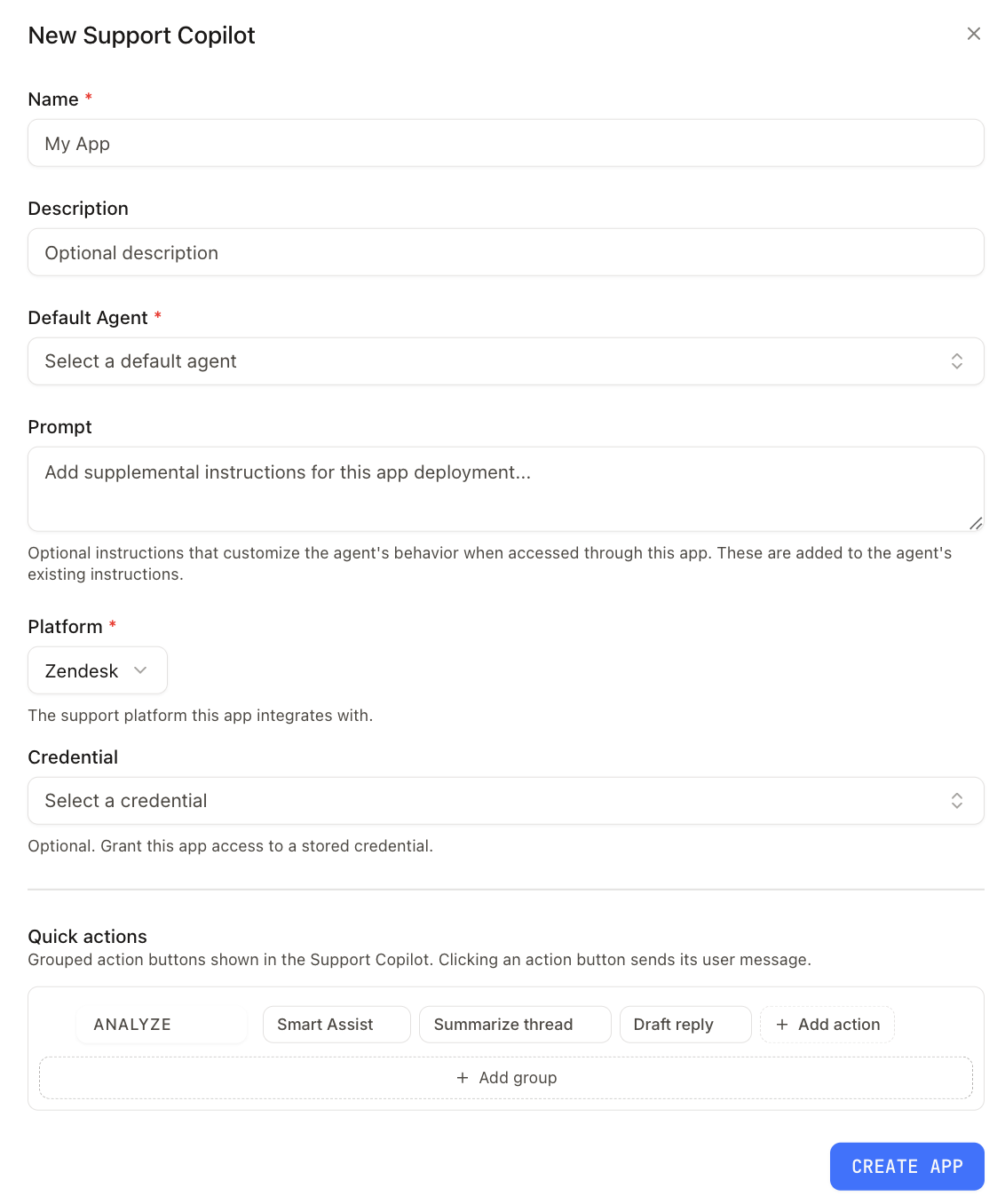
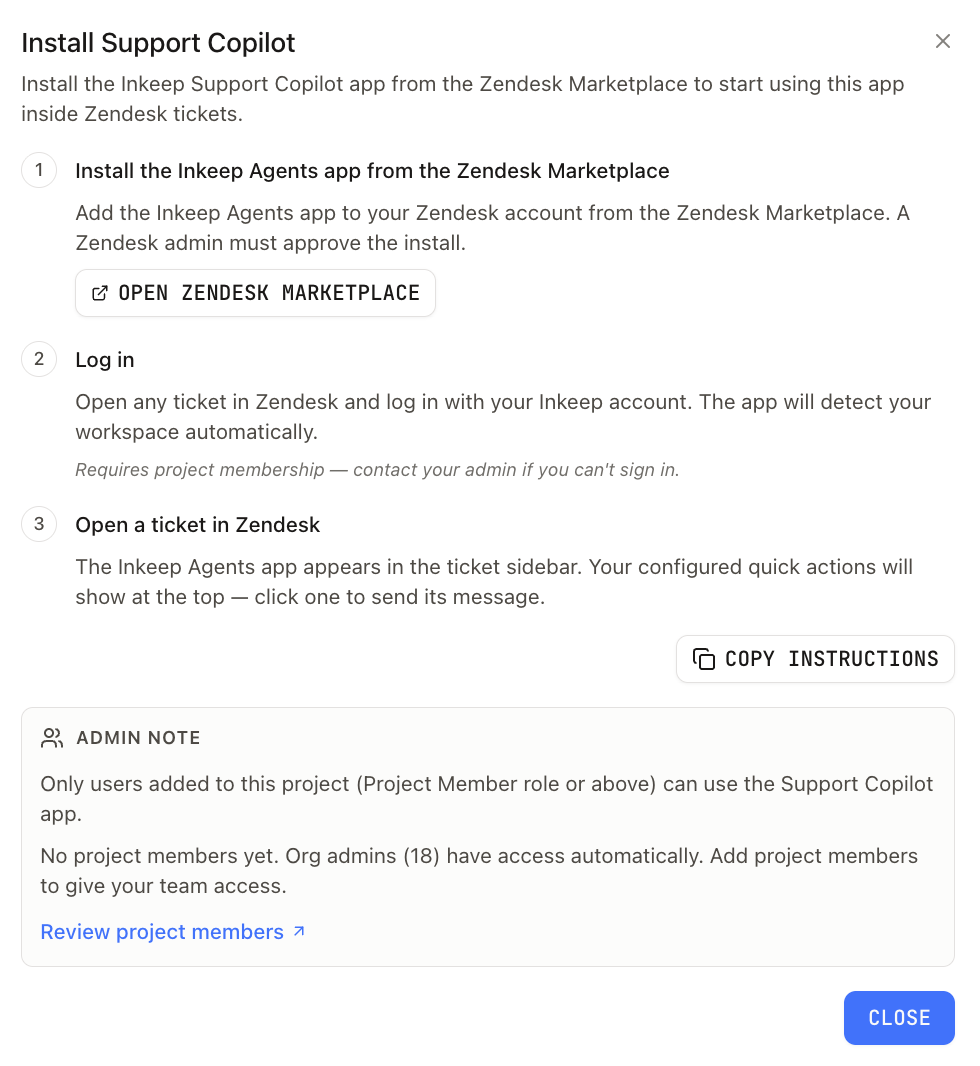
 ## Overview
In this tutorial, you'll build an Autoreply agent in the Inkeep Visual Builder. When a new ticket lands in Zendesk, the agent will:
1. Read the customer's question
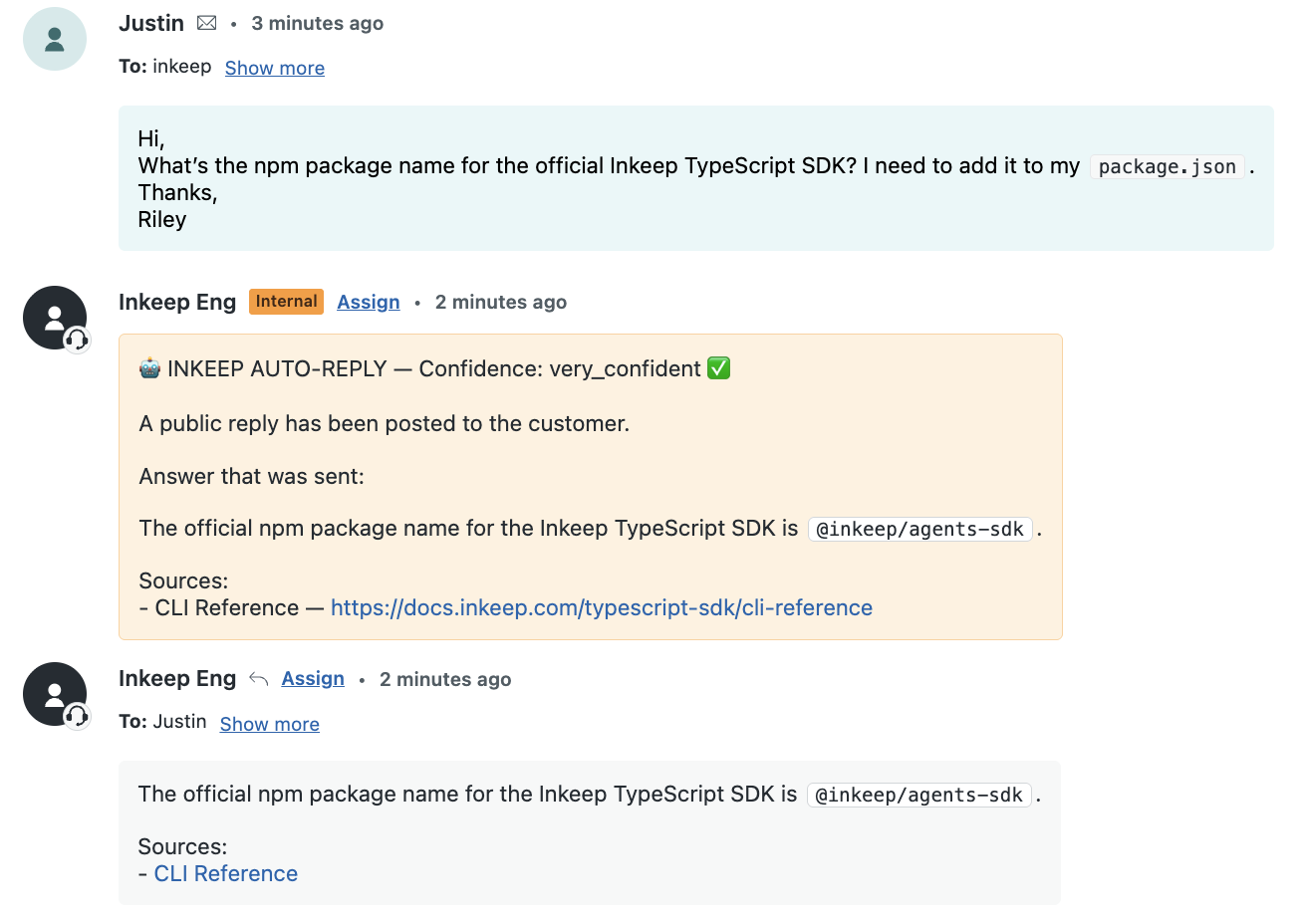
2. Ask a confidence-aware KB tool — it returns an `answer`, a `confidence` level, and `citations`
3. **Always** post an internal audit note with the answer + confidence
4. **Only when confidence is `very_confident`**, also post a public reply to the customer
The contract is: high confidence → customer gets replied to; anything less → a human takes over. You get deflection on the easy stuff and human review on the hard stuff, automatically.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* A Zendesk org where the agent can post both internal and public comments
* A **Zendesk MCP server** registered in your project, with tools that post internal comments **and** public comments. If you don't have one yet, see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers).
## Expose the Inkeep QA confidence tool
Inkeep's QA API answers a question against your knowledge base, and it can call **custom tools you define** as part of answering. You'll use that capability to grade each answer with a `confidence` level and return it alongside the `answer` and its `citations`. That confidence level is what makes safe auto-reply possible — it's how the agent knows whether the KB is sure enough about the answer to send it to a customer.
The five confidence levels:
| Level | Meaning |
| -------------------- | ------------------------------------------------------------- |
| `very_confident` | The KB has a direct answer. Safe to send publicly. |
| `somewhat_confident` | Partial match. Don't auto-reply — human handles. |
| `not_confident` | KB has tangential info at best. Don't auto-reply. |
| `no_sources` | KB has nothing relevant. Don't auto-reply. |
| `other` | Anything else (off-topic, too vague, etc.). Don't auto-reply. |
To make this available to your agent, expose it as a tool called `ask_with_confidence(question) → { answer, confidence, citations }`. The cleanest way is a thin Custom MCP that wraps the Inkeep QA API — see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) for the Next.js template and the `inkeep add --mcp` CLI flow. Deploy it and grab the public URL.
## Overview
In this tutorial, you'll build an Autoreply agent in the Inkeep Visual Builder. When a new ticket lands in Zendesk, the agent will:
1. Read the customer's question
2. Ask a confidence-aware KB tool — it returns an `answer`, a `confidence` level, and `citations`
3. **Always** post an internal audit note with the answer + confidence
4. **Only when confidence is `very_confident`**, also post a public reply to the customer
The contract is: high confidence → customer gets replied to; anything less → a human takes over. You get deflection on the easy stuff and human review on the hard stuff, automatically.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* A Zendesk org where the agent can post both internal and public comments
* A **Zendesk MCP server** registered in your project, with tools that post internal comments **and** public comments. If you don't have one yet, see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers).
## Expose the Inkeep QA confidence tool
Inkeep's QA API answers a question against your knowledge base, and it can call **custom tools you define** as part of answering. You'll use that capability to grade each answer with a `confidence` level and return it alongside the `answer` and its `citations`. That confidence level is what makes safe auto-reply possible — it's how the agent knows whether the KB is sure enough about the answer to send it to a customer.
The five confidence levels:
| Level | Meaning |
| -------------------- | ------------------------------------------------------------- |
| `very_confident` | The KB has a direct answer. Safe to send publicly. |
| `somewhat_confident` | Partial match. Don't auto-reply — human handles. |
| `not_confident` | KB has tangential info at best. Don't auto-reply. |
| `no_sources` | KB has nothing relevant. Don't auto-reply. |
| `other` | Anything else (off-topic, too vague, etc.). Don't auto-reply. |
To make this available to your agent, expose it as a tool called `ask_with_confidence(question) → { answer, confidence, citations }`. The cleanest way is a thin Custom MCP that wraps the Inkeep QA API — see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) for the Next.js template and the `inkeep add --mcp` CLI flow. Deploy it and grab the public URL.
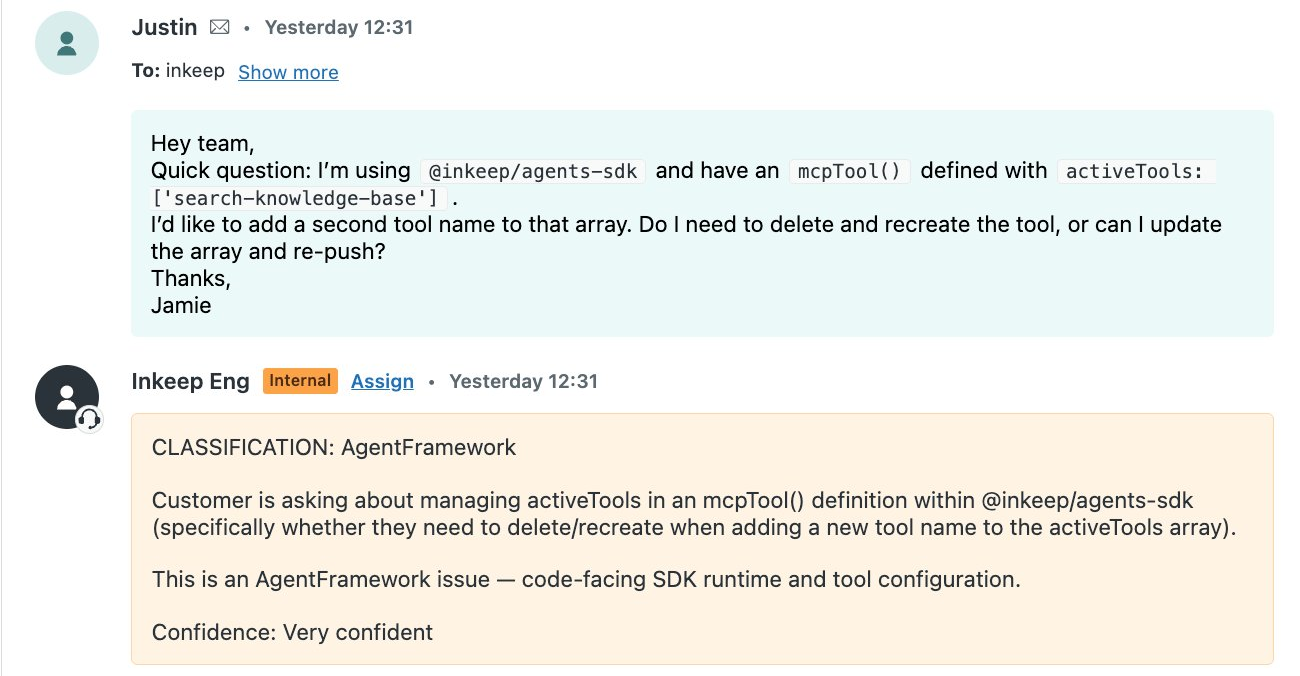 ## Overview
In this tutorial, you'll build a ticket-routing agent in the Inkeep Visual Builder. When a new ticket lands in Zendesk, the agent will:
1. Read the ticket and identify the actual problem
2. Pick the team that owns that problem area
3. Write the team tag to a Zendesk custom field
The result is an inbox that sorts itself.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* A Zendesk org where you can create a custom field for ticket routing (e.g., a dropdown field named "Ticket type" with one value per team)
* A **Zendesk MCP server** registered in your project, with a tool that writes a value to a ticket's custom field. If you don't have one yet, see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) for how to wrap the Zendesk API as an MCP server.
## Create the Classifier agent
## Overview
In this tutorial, you'll build a ticket-routing agent in the Inkeep Visual Builder. When a new ticket lands in Zendesk, the agent will:
1. Read the ticket and identify the actual problem
2. Pick the team that owns that problem area
3. Write the team tag to a Zendesk custom field
The result is an inbox that sorts itself.
## Prerequisites
* Access to Inkeep Enterprise — [schedule a demo](https://inkeep.com/schedule-demo) if you don't have it yet
* A Zendesk org where you can create a custom field for ticket routing (e.g., a dropdown field named "Ticket type" with one value per team)
* A **Zendesk MCP server** registered in your project, with a tool that writes a value to a ticket's custom field. If you don't have one yet, see [Build Custom MCP Servers](/guides/mcp-servers/custom-mcp-servers) for how to wrap the Zendesk API as an MCP server.
## Create the Classifier agent